目录
目录
flink 怎么判断是本地环境还是集群环境的?
flink 的接口都是声明式的,那么到底把我们的接口解析或者封装成什么样进行执行了?
flink 怎么判断是本地环境还是集群环境的?
环境判断
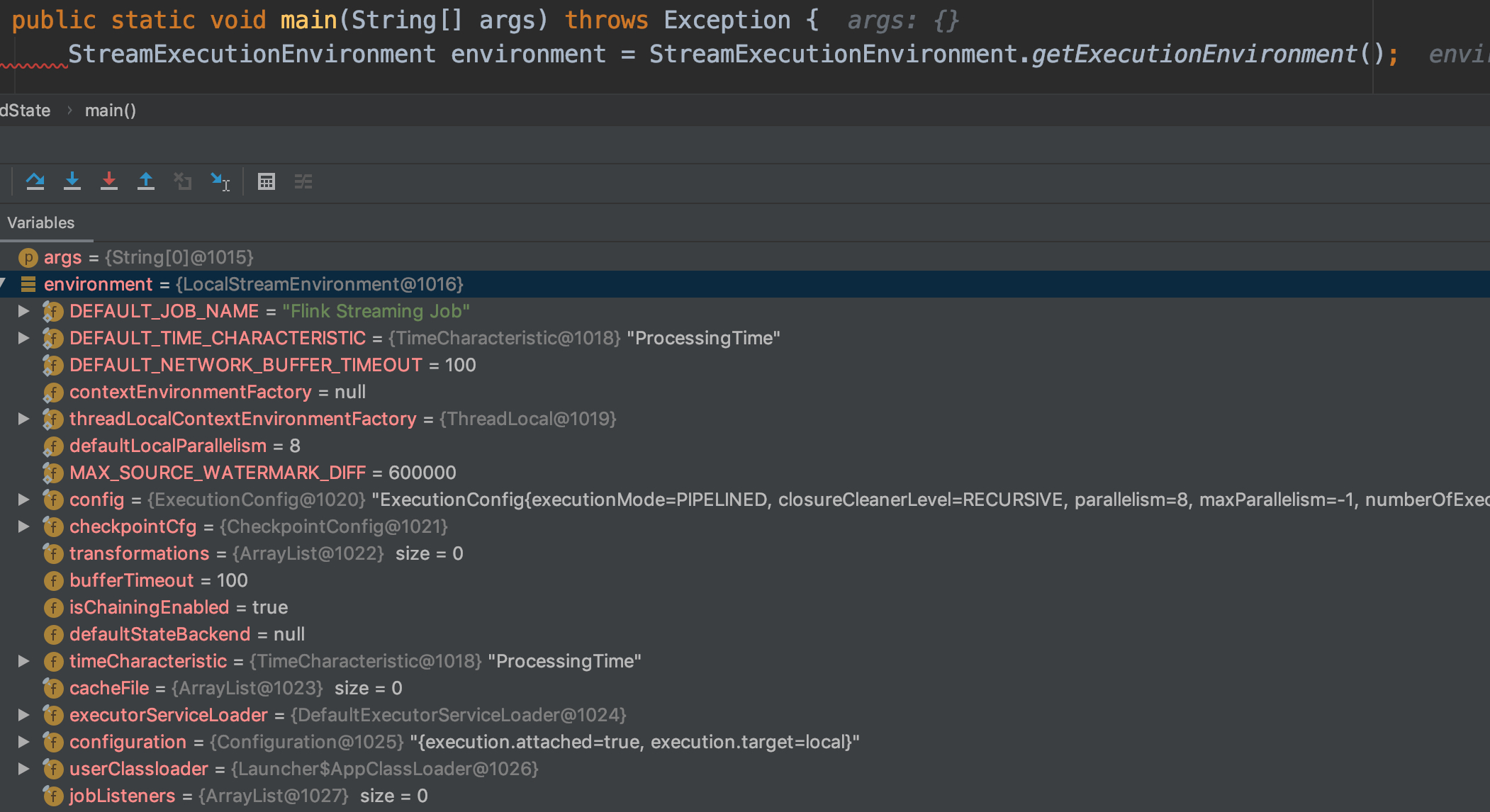
通过 debug StreamExecutionEnvironment.getExecutionEnvironment(); 可以定位到下面的代码
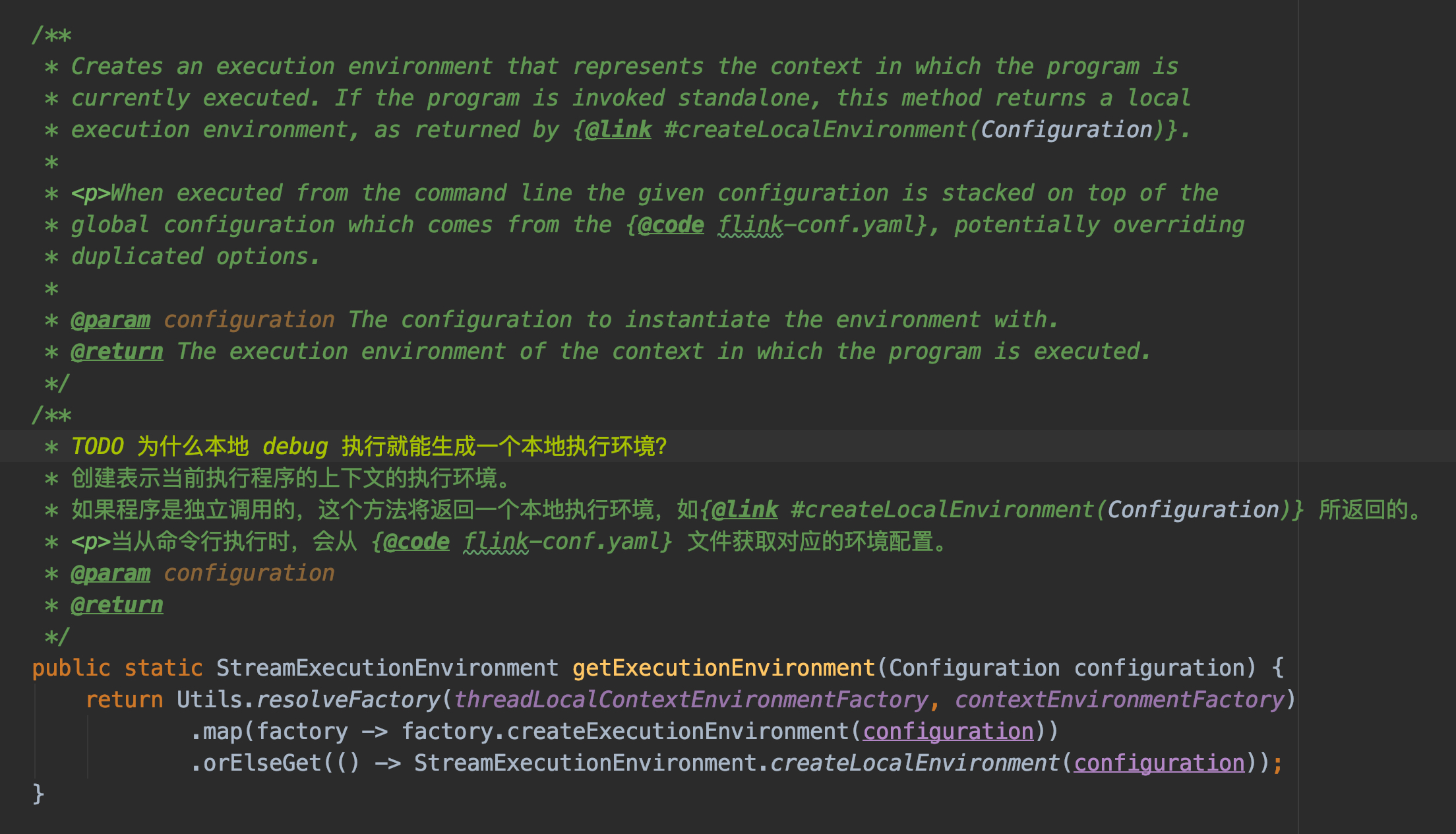
我们可以看注释,解释一下,基本流程如下:
- 先尝试获取本地环境,即从 threadLocalContextEnvironmentFactory 获取环境配置
- 获取不到本地环境配置,就获取外部环境配置,即从 contextEnvironmentFactory 获取环境配置
1 | public static StreamExecutionEnvironment getExecutionEnvironment(Configuration configuration) { |
那么问题来了,当集群环境时,是如何将 StreamExecutionEnvironmentFactory 到 ThreadLocal 中?
集群环境
通过 bin/flink run ….命令提交jar包到集群运行命令时,该脚本会调用org.apache.flink.client.cli.CliFrontend 来运行用户程序,如下:
1 | Add HADOOP_CLASSPATH to allow the usage of Hadoop file systems |
在CliFrontend中依次执行以下方法 main() ->parseParameters() -> run() ->executeProgram()
1 | protected void executeProgram(final Configuration configuration, final PackagedProgram program) |
在org.apache.flink.client.ClientUtils的executeProgram()中调用StreamContextEnvironment.setAsContext(…),StreamContextEnvironment继承自StreamExecutionEnvironment。setAsContext()代码如下
1 | StreamContextEnvironment.setAsContext( |
创建生成运行环境的工厂类实例,在initializeContextEnvironment()方法中把实例放到StreamExecutionEnvironment类的静态属性threadLocalContextEnvironmentFactory 中,代码如下
1 | protected static void initializeContextEnvironment(StreamExecutionEnvironmentFactory ctx) { |
这样在用户程序StreamExecutionEnvironment.getExecutionEnvironment()时,获取到的运行环境就是StreamContextEnvironment类的setAsContext()方法中生成的
本地运行环境LocalStreamEnvironment和 独立集群、flink on yarn等运行环境StreamContextEnvironment 的主要区别在于,他们的成员属性 configuration 不同。LocalStreamEnvironment 中是创建的空键值对(new Configuration()),而StreamContextEnvironment 是通过CliFrontend 生成的Configuration对象。
flink 的接口都是声明式的,那么到底把我们的接口解析或者封装成什么样进行执行了?
声明式编程
https://www.cnblogs.com/sirkevin/p/8283110.html
flink runtime 架构概览

从上述整体的架构可以看出来,flink 的架构是区分客户端和服务端的,我们在客户端编写号代码,然后提交代码到服务端进行运行
而且 flink 的接口是声明式的,那么这个过程中肯定会涉及到代码的包装执行。具体代码进行了哪些包装,如下图 4 个图的流程就是 flink 从客户端提交代码到服务端具体执行的整个解析过程:
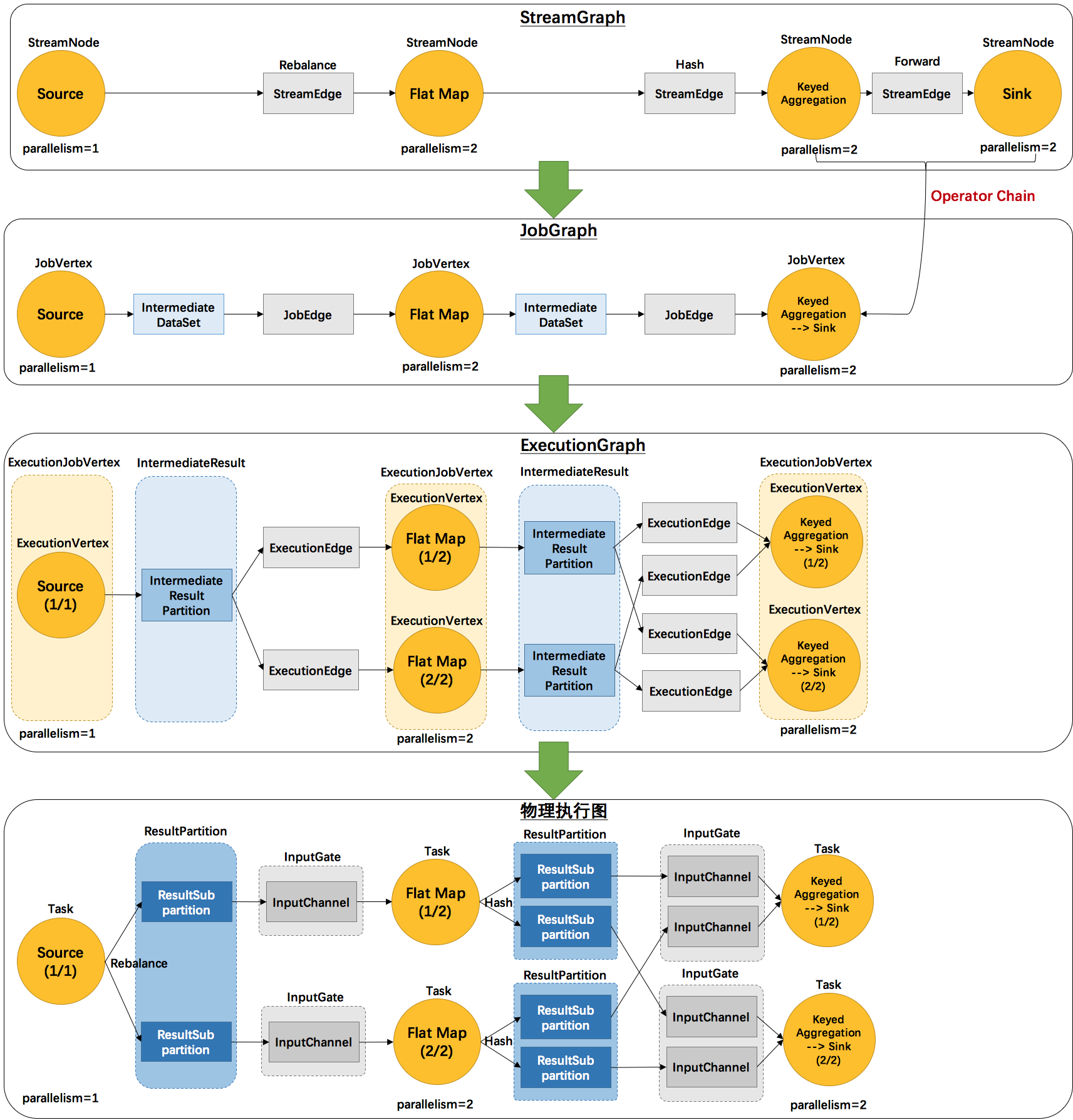
1. StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
- StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
- StreamEdge:表示连接两个 StreamNode 的边。
- 是在客户端生成的,在 flink 中是一个具体的数据结构。
2. JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
- JobVertex:经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个 JobVertex,即一个 JobVertex 包含一个或多个 operator,JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。
- IntermediateDataSet:表示 JobVertex 的输出,即经过 operator 处理产生的数据集。producer 是 JobVertex,consumer 是 JobEdge。
- JobEdge:代表了 job graph 中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过 JobEdge 由 IntermediateDataSet 传递给目标 JobVertex。
- 是在客户端生成的,在 flink 中是一个具体的数据结构。
3. ExecutionGraph:JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
- ExecutionJobVertex:和 JobGraph 中的 JobVertex 一一对应。每一个 ExecutionJobVertex 都有和并发度一样多的 ExecutionVertex。
- ExecutionVertex:表示 ExecutionJobVertex 的其中一个并发子任务,输入是 ExecutionEdge,输出是 IntermediateResultPartition。
- IntermediateResult:和 JobGraph 中的 IntermediateDataSet 一一对应。一个 IntermediateResult 包含多个 IntermediateResultPartition,其个数等于该 operator 的并发度。
- IntermediateResultPartition:表示 ExecutionVertex 的一个输出分区,producer 是 ExecutionVertex,consumer 是若干个 ExecutionEdge。
- ExecutionEdge:表示 ExecutionVertex 的输入,source 是 IntermediateResultPartition,target 是 ExecutionVertex。source 和 target 都只能是一个。
- Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM 和 TM 之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
- 是在服务端生成的,在 flink 中是一个具体的数据结构。
4. 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
- Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
- ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。
- ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
- InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。
- InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。
- 是在服务端生成的,不是具体的数据结构,而是实际的物理执行的一个图描述。
那么 Flink 为什么要设计这4张图呢,其目的是什么呢?Spark 中也有多张图,数据依赖图以及物理执行的 DAG。其目的都是一样的,就是解耦,每张图各司其职,每张图对应了 Job 不同的阶段,更方便做该阶段的事情。我们给出更完整的 Flink Graph 的层次图。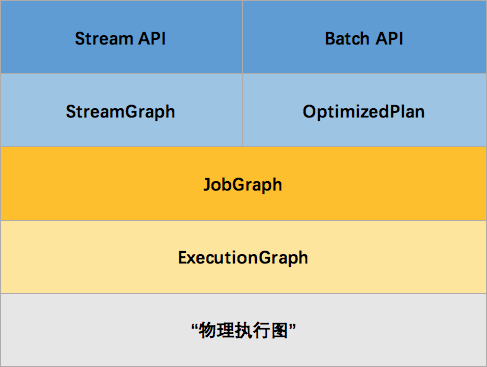
首先我们看到,JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。StreamGraph 是由 Stream API 转换而来的。为什么 API 不直接转换成 JobGraph?因为,Batch 和 Stream 的图结构和优化方法有很大的区别,比如 Batch 有很多执行前的预分析用来优化图的执行,而这种优化并不普适于 Stream,所以通过 OptimizedPlan 来做 Batch 的优化会更方便和清晰,也不会影响 Stream。JobGraph 的责任就是统一 Batch 和 Stream 的图,用来描述清楚一个拓扑图的结构,并且做了 chaining 的优化,chaining 是普适于 Batch 和 Stream 的,所以在这一层做掉。ExecutionGraph 的责任是方便调度和各个 tasks 状态的监控和跟踪,所以 ExecutionGraph 是并行化的 JobGraph。而“物理执行图”就是最终分布式在各个机器上运行着的tasks了。所以可以看到,这种解耦方式极大地方便了我们在各个层所做的工作,各个层之间是相互隔离的。
如何生成 StreamGraph?
基于 1.12 源码。
StreamGraph 是在客户端构造的,这意味着我们可以在本地通过调试观察 StreamGraph 的构造过程。
StreamGraph 生成的整个入口函数执行顺序如下:
1 | // 开始执行代码 |
可以看到初始化 StreamGraphGenerator 需要传入四个参数,其中我们最需要关心的参数就是第一个 transformations;
Transformation 是用来干啥的?
Transformation 其实就是我们在代码中定义的各种转换操作,比如 map,filter,flatmap,keyby 等转换操作,经过 flink 的简单包装之后成为 Transformation,其之间的具体关系如下图: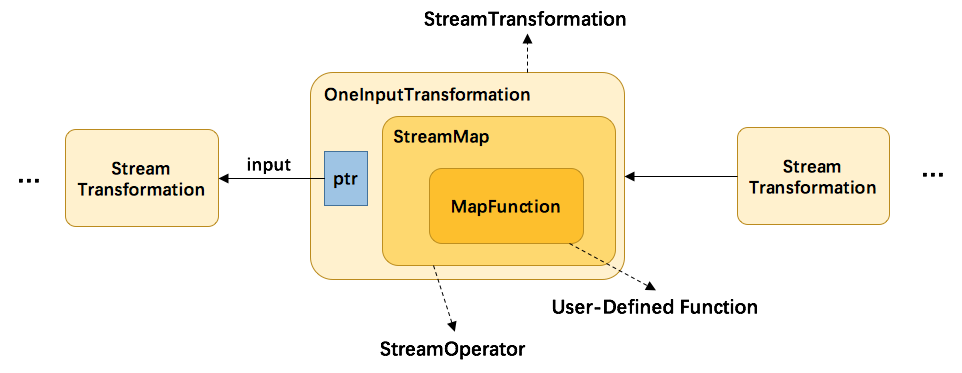
经过这么多层的封装,肯定是为用户自定义算子增强或者填充了一些功能,具体是哪些功能呢?
举个例子:
1 | environment |
先 debug 到 map(t -> t),然后我们来看 env 中的变量: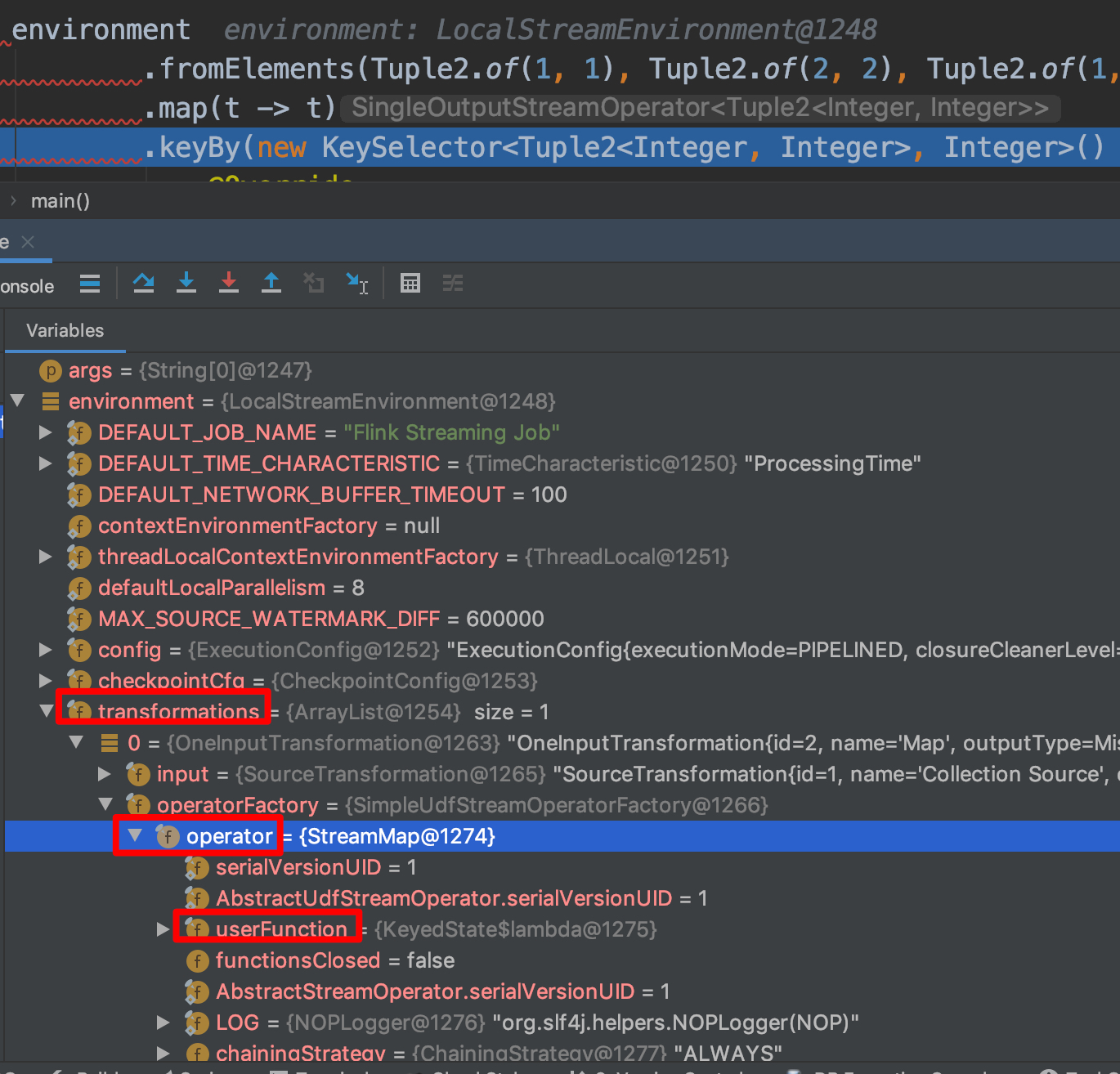
从这个变量来看就可以和上面的图映射上了,分别是 OneInputTransformation -> StreamMap -> UserFunction;
我们仔细看这些变量,来查看到底哪些增强了哪些功能。
1. StreamMap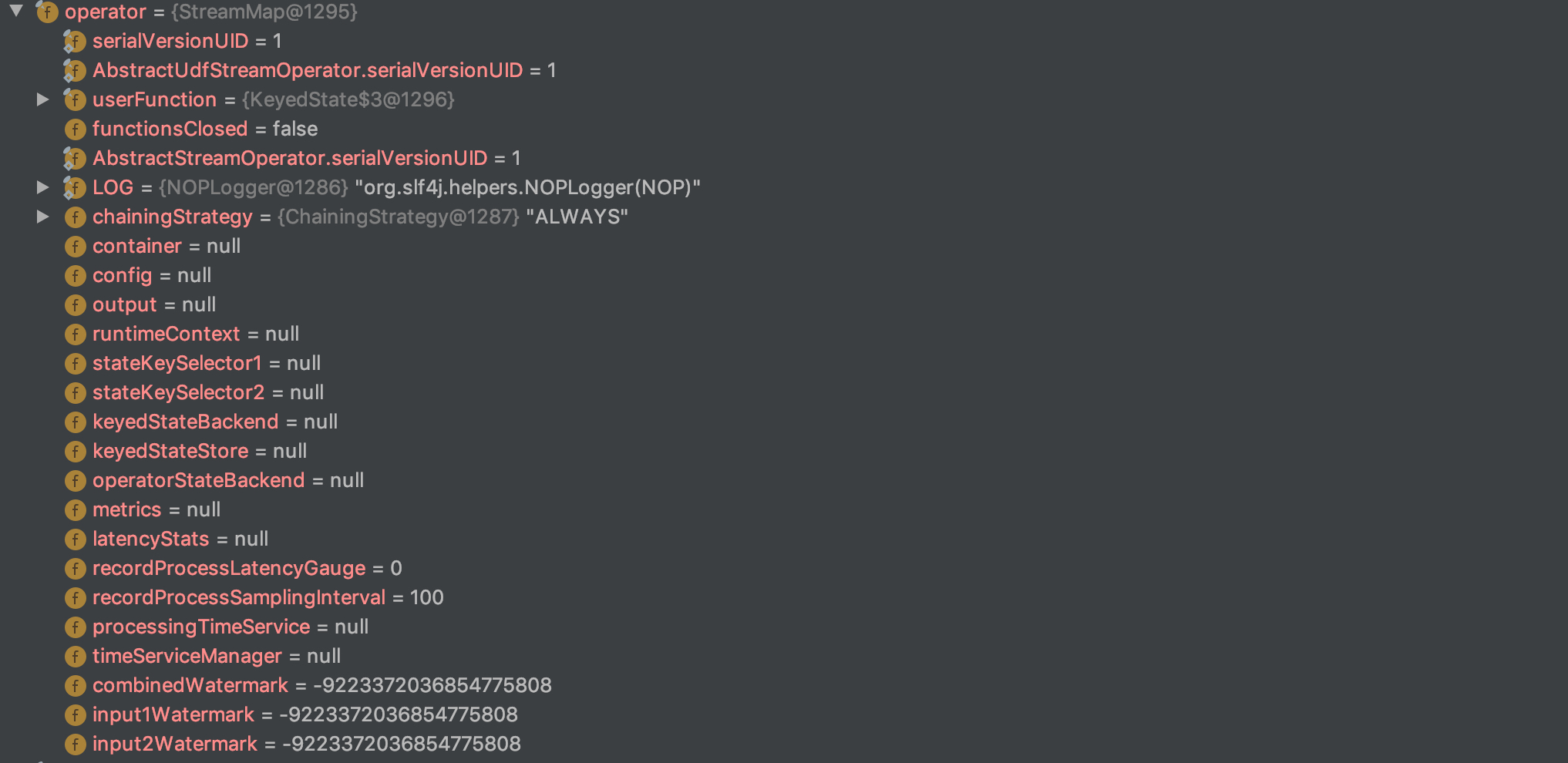
- ChainingStrategy:flink 的优化策略中有本地性优化,就是会检查前一个算子和后一个算子是否能够 chain 在一起,这样的话就可以把数据的 shuffle 本地化,而 ChainingStrategy 就是这个优化的一个决定条件;
2. OneInputTransformation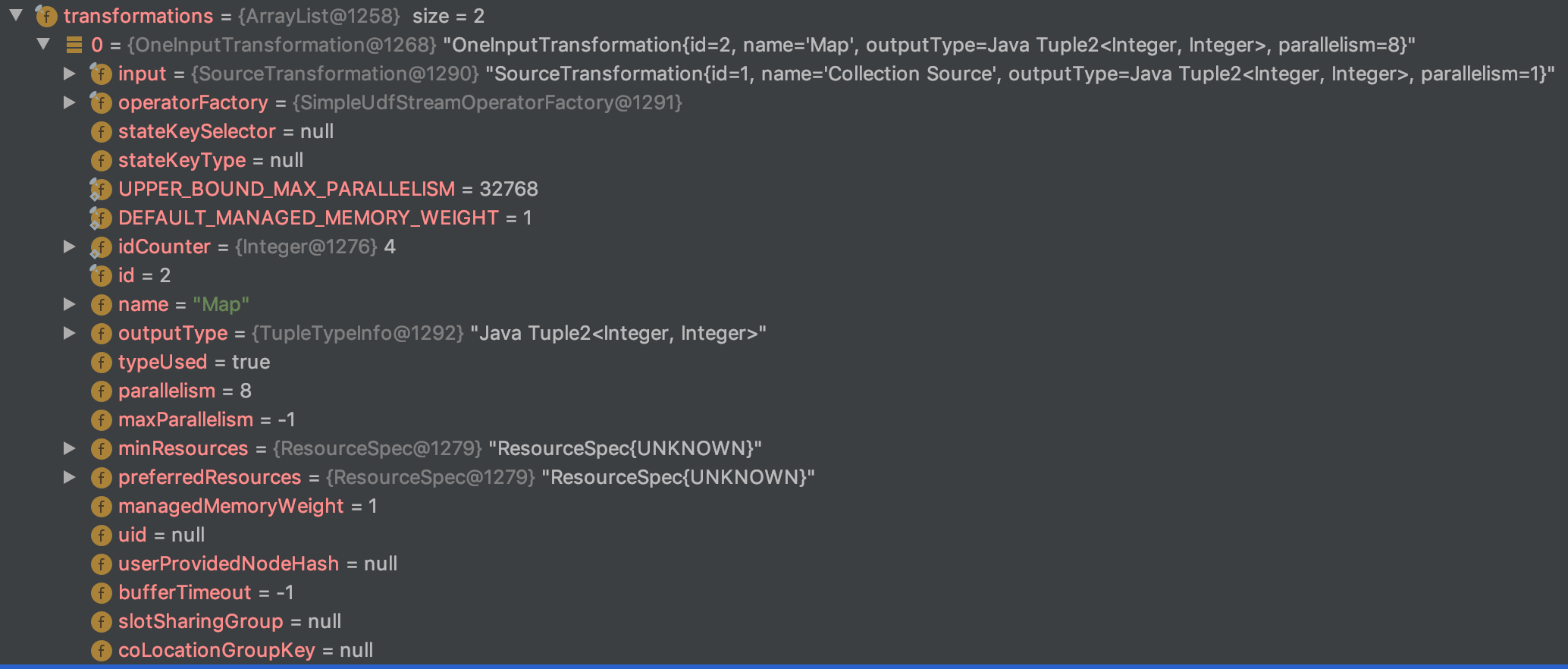
- input:负责将上游 Transformation 进行存储,之后可以利用这个上下游关系串联整个 DAG;
- stateKeySelector:如果是 keyBy 后接 map,则 map 算子就会作用在具体 key 的数据上,这个就是对应的 KeySelector;
- stateKeyType:同 stateKeySelector,存储的是具体的 key 的类型信息;
- outputType:输出数据的类型信息;
- typeUsed:TODO;
- parallelism:算子并发度信息;
- maxParallelism:算子最大并发度信息;
- minResources,preferredResources:用户自定义细粒度的资源配置(这个 feature 还没有开放给用户);
- managedMemoryWeight:TODO
- uid:状态恢复时的状态唯一标识,恢复时会根据状态中的 uid 和算子中的 uid 进行匹配,匹配不到状态就不能恢复;
- userProvidedNodeHash:TODO
- bufferTimeout:TODO
- slotSharingGroup:可以进行 slot 分享的 group 标识;
- coLocationGroupKey:TODO
注意不同的 Transformation 做了不同的增强,常见的 Transformation 有以下几类,大家可以自己进行 debug 查看都有哪些增强。
另外,并不是每一个 Transformation 都会转换成 runtime 层中物理操作。有一些只是逻辑概念,比如 union、split/select、partition等。如下图所示的转换树,在运行时会优化成下方的操作图。
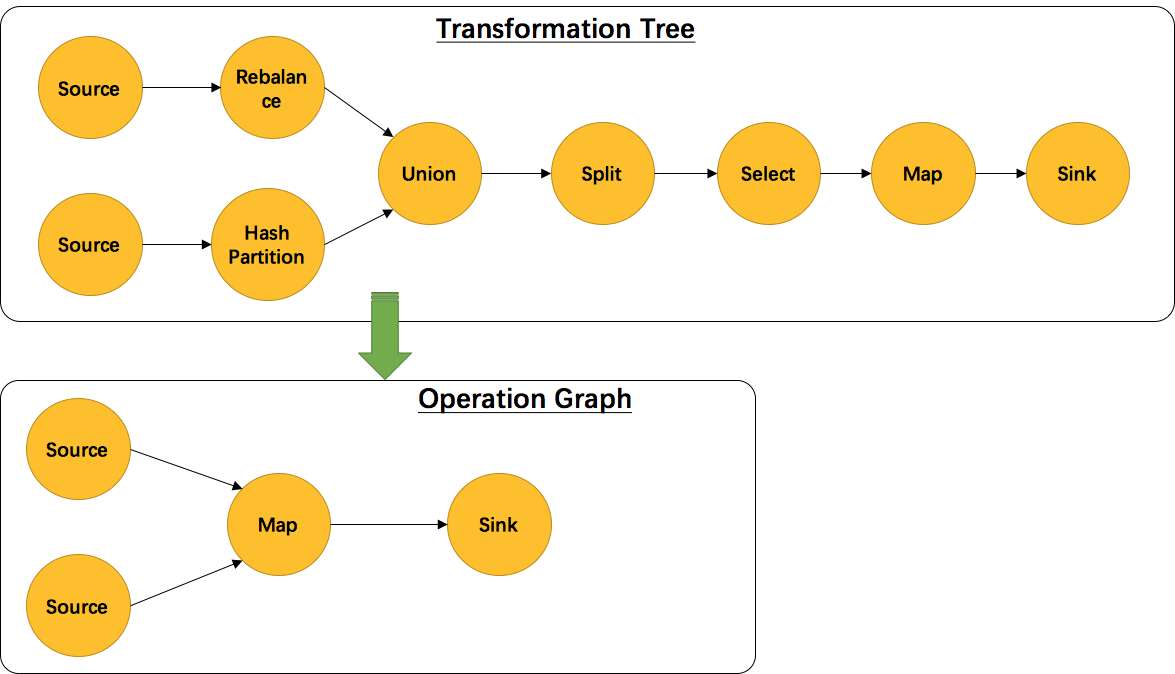
union、split/select、partition 中的信息会被写入到 Source –> Map 的边中。通过源码也可以发现,UnionTransformation,SplitTransformation,SelectTransformation,PartitionTransformation 由于不包含具体的操作所以都没有 StreamOperator 成员变量,而其他 Transformation 的子类基本上都有。
Transformation 的作用:
- 1:用户在编写时定义的上下游算子。即串联用户定义的原始 DAG 上下游信息。
- 2:用户在编写时定义的输入输出类型。即尝试获取算子输入输出类型信息以及对应的序列化器。
- 3:用户在编写时定义的算子并行度。即计算出每一个算子的并行度信息。
StreamGraph 是用来干啥的?
先来看看 StreamGraph 实例

Transformation -> StreamGraph
我们来看看 StreamGraph 构建完成之后最主要的内容包含哪些?

DataStream 上的每一个 Transformation 都对应了一个 StreamOperator,StreamOperator是运行时的具体实现,会决定UDF(User-Defined Funtion)的调用方式。下图所示为 StreamOperator 的类图(点击查看大图):
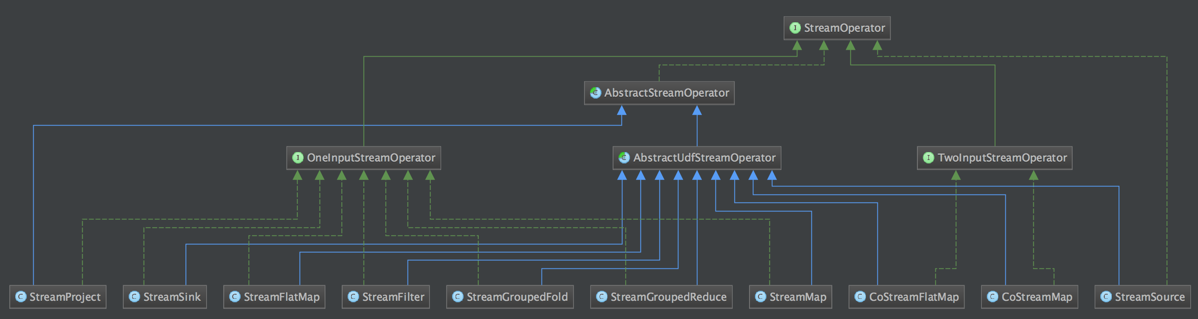
可以发现,所有实现类都继承了AbstractStreamOperator。另外除了 project 操作,其他所有可以执行UDF代码的实现类都继承自AbstractUdfStreamOperator,该类是封装了UDF的StreamOperator。UDF就是实现了Function接口的类,如MapFunction,FilterFunction。
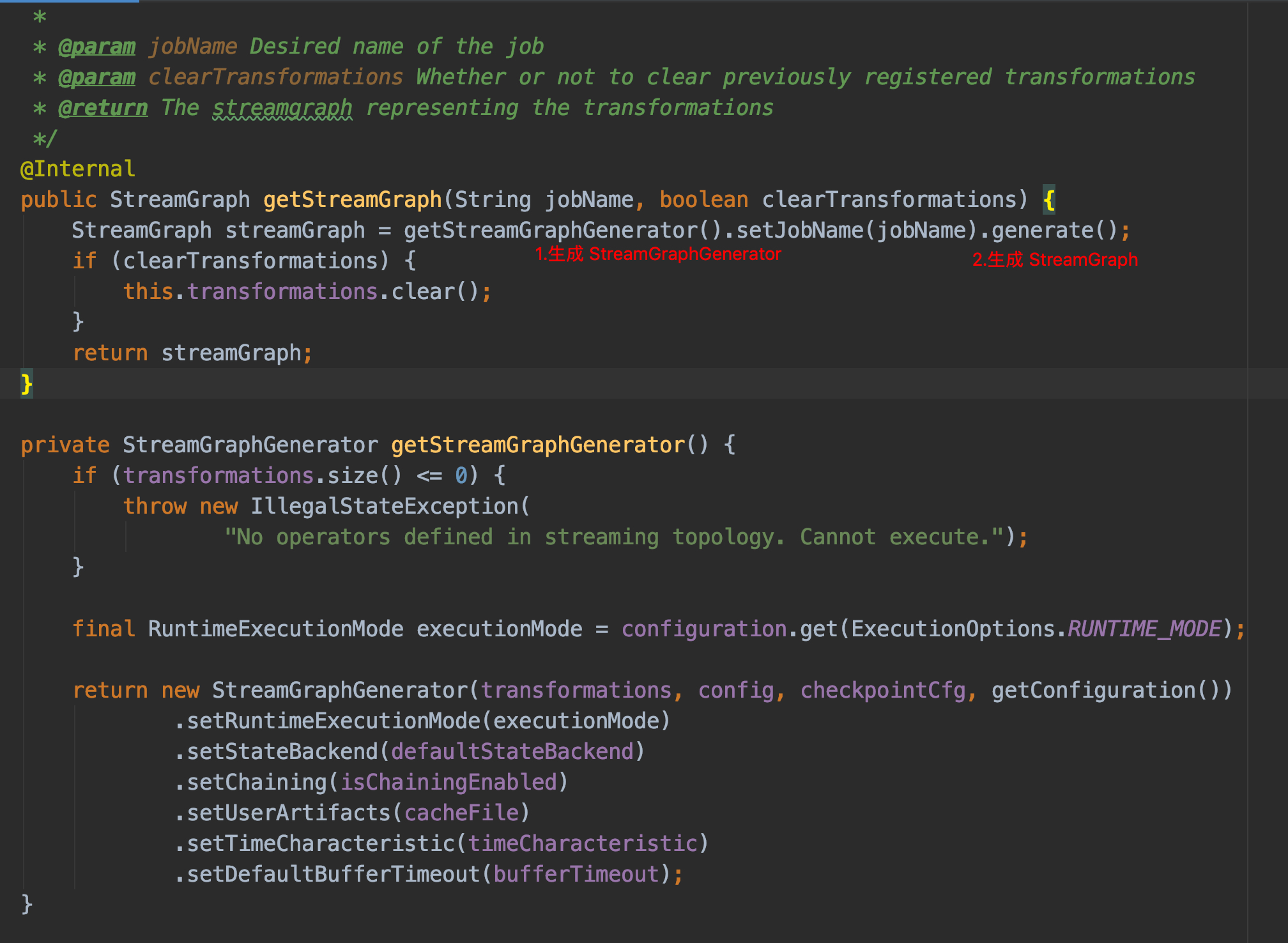
我们通过在 DataStream 上做了一系列的转换(map、filter等)得到了 Transformation 集合,然后通过 StreamGraphGenerator.generate 获得 StreamGraph,该方法的源码如下:
StreamGraphGenerator 中其实包含的最主要的内容就是各个类型 Transformation 的 Translator。如图所示;
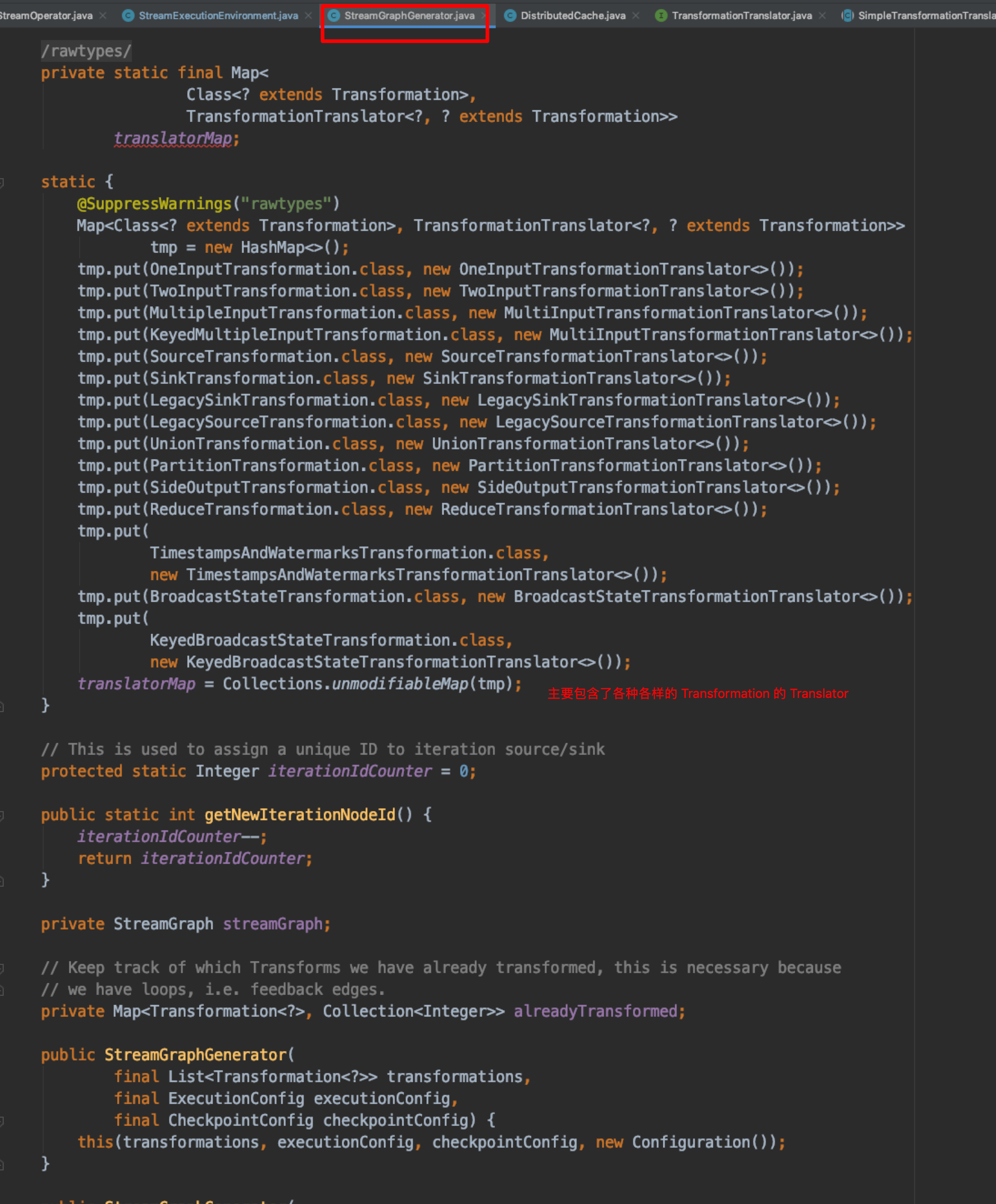
每个 Translator 会将 Transformation 转换为对应的 StreamNode 或者 StreamEdge。
如何生成 JobGraph?
我们来看看 JobGraph 构建完成之后最主要的内容包含哪些?

JobGraph 的相关数据结构主要在 org.apache.flink.runtime.jobgraph 包中。构造 JobGraph 的代码主要集中在 StreamingJobGraphGenerator 类中,入口函数是 StreamingJobGraphGenerator.createJobGraph()。我们首先来看下 StreamingJobGraphGenerator 的核心源码:
StreamNode 转成 JobVertex,StreamEdge 转成 JobEdge,JobEdge 和 JobVertex 之间创建 IntermediateDataSet 来连接。关键点在于将多个 SteamNode chain 成一个 JobVertex的过程,这部分源码比较绕,有兴趣的同学可以结合源码单步调试分析。下一章将会介绍 JobGraph 提交到 JobManager 后是如何转换成分布式化的 ExecutionGraph 的。
每个 JobVertex 都会对应一个可序列化的 StreamConfig, 用来发送给 JobManager 和 TaskManager。最后在 TaskManager 中起 Task 时,需要从这里面反序列化出所需要的配置信息, 其中就包括了含有用户代码的StreamOperator。
setChaining会对source调用createChain方法,该方法会递归调用下游节点,从而构建出node chains。createChain会分析当前节点的出边,根据Operator Chains中的chainable条件,将出边分成chainalbe和noChainable两类,并分别递归调用自身方法。之后会将StreamNode中的配置信息序列化到StreamConfig中。如果当前不是chain中的子节点,则会构建 JobVertex 和 JobEdge相连。如果是chain中的子节点,则会将StreamConfig添加到该chain的config集合中。一个node chains,除了 headOfChain node会生成对应的 JobVertex,其余的nodes都是以序列化的形式写入到StreamConfig中,并保存到headOfChain的 CHAINED_TASK_CONFIG 配置项中。直到部署时,才会取出并生成对应的ChainOperators,具体过程请见理解 Operator Chains。

