实时新增类指标标准化处理方案
实时指标整个链路开发过程中的一些经验。
实时新增类指标
大体上可以将实时新增类指标以以下两种维度进行分类。
identity id 类型维度
| identity id 类型 | 备注 |
|---|---|
| number(long) 类型 identity id | 数值类型 identity id 的好处在于可以使用 Bitmap 类组件做到精确去重。 |
| 字符类型 identity id | 字符类型 identity id 去重相对复杂,有两种方式,在误差允许范围之内使用 BloomFilter 进行去重,或者使用 key-value 组件进行精确去重。 |
产出数据类型维度
| 产出数据类型 | 备注 |
|---|---|
| 明细类数据 | 此类数据一般是要求将新增的数据明细产出,uv 的含义是做过滤,产出的明细数据中的 identity id 不会有重复。输出明细数据的好处在于,我们可以在下游使用 OLAP 引擎对明细数据进行各种维度的聚合计算,从而很方便的产出不同维度下的 uv 数据。 |
| 聚合类数据 | 将一个时间窗口内的 uv 进行聚合,并且可以计算出分维度的 uv,其产出数据一般都是[维度 + uv_count],但是这里的维度一般情况下是都是固定维度。如果需要拓展则需要改动源码。 |
计算链路
因此新增产出的链路多数就是以上两种维度因子的相互组合。
number(long) 类型 identity id
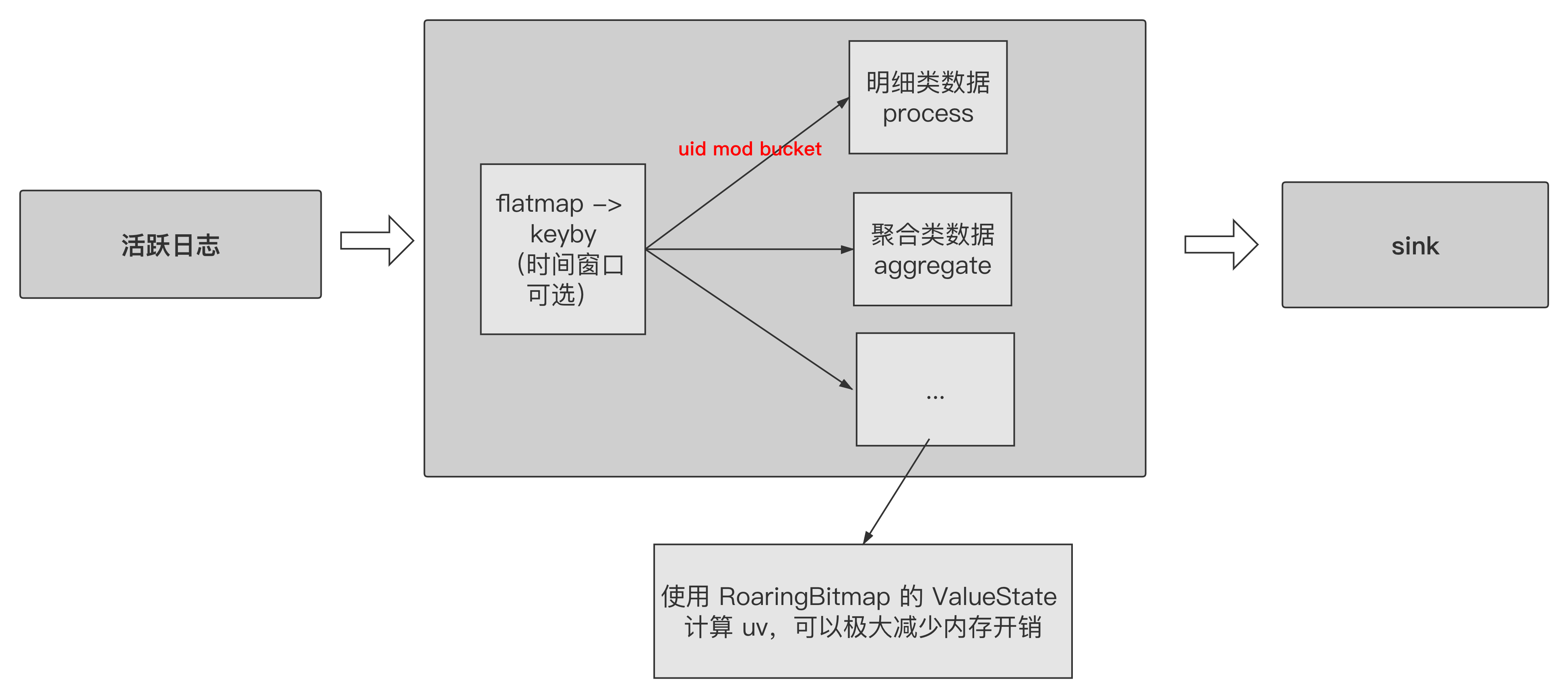
代码示例:
1 | public interface RoaringBitmapDuplicateable<Model> { |
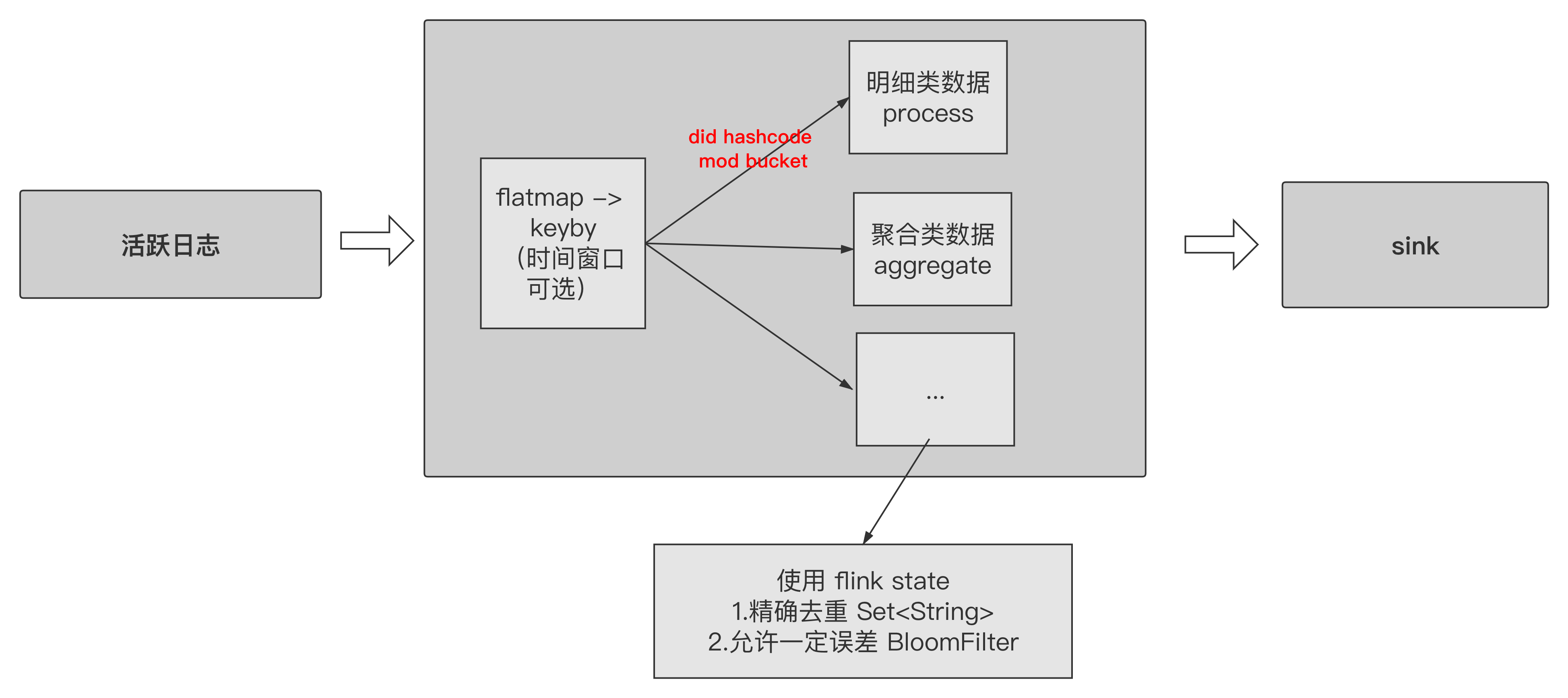
字符类型 identity id
使用 Flink state
使用 key-value 外存
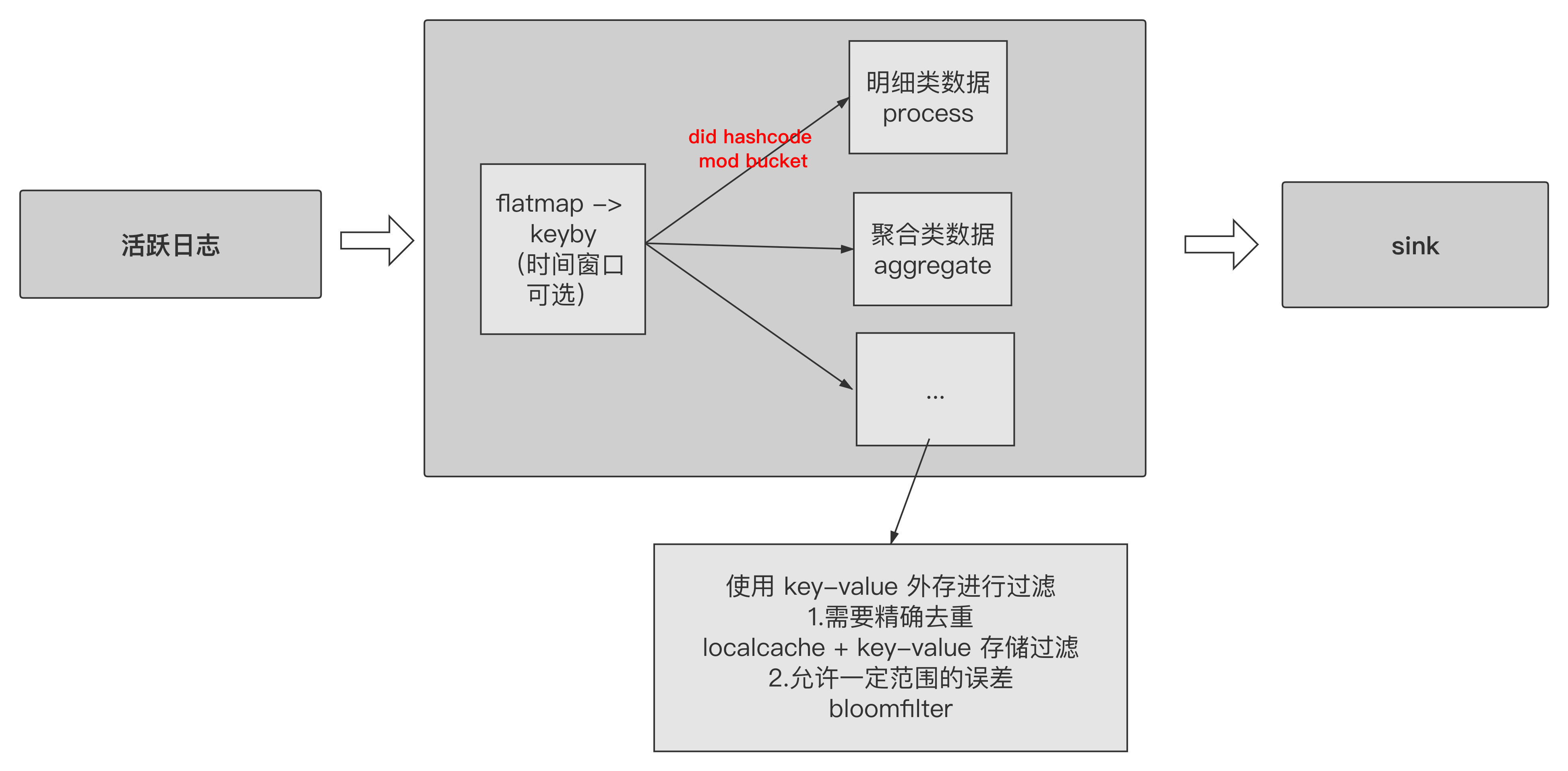
如果选用的是 Redis 作为 key-value 过滤,那么这里会有一个巧用 Redis bit 特性的优化。举一个一般场景下的方案与使用 Redis bit 特性的方案做对比:
场景:假如需要同一天有几十场活动,并且都希望计算出这几十场活动的 uv,那么我们就可以按照下图设计 Redis bit 结构。
通常方案:
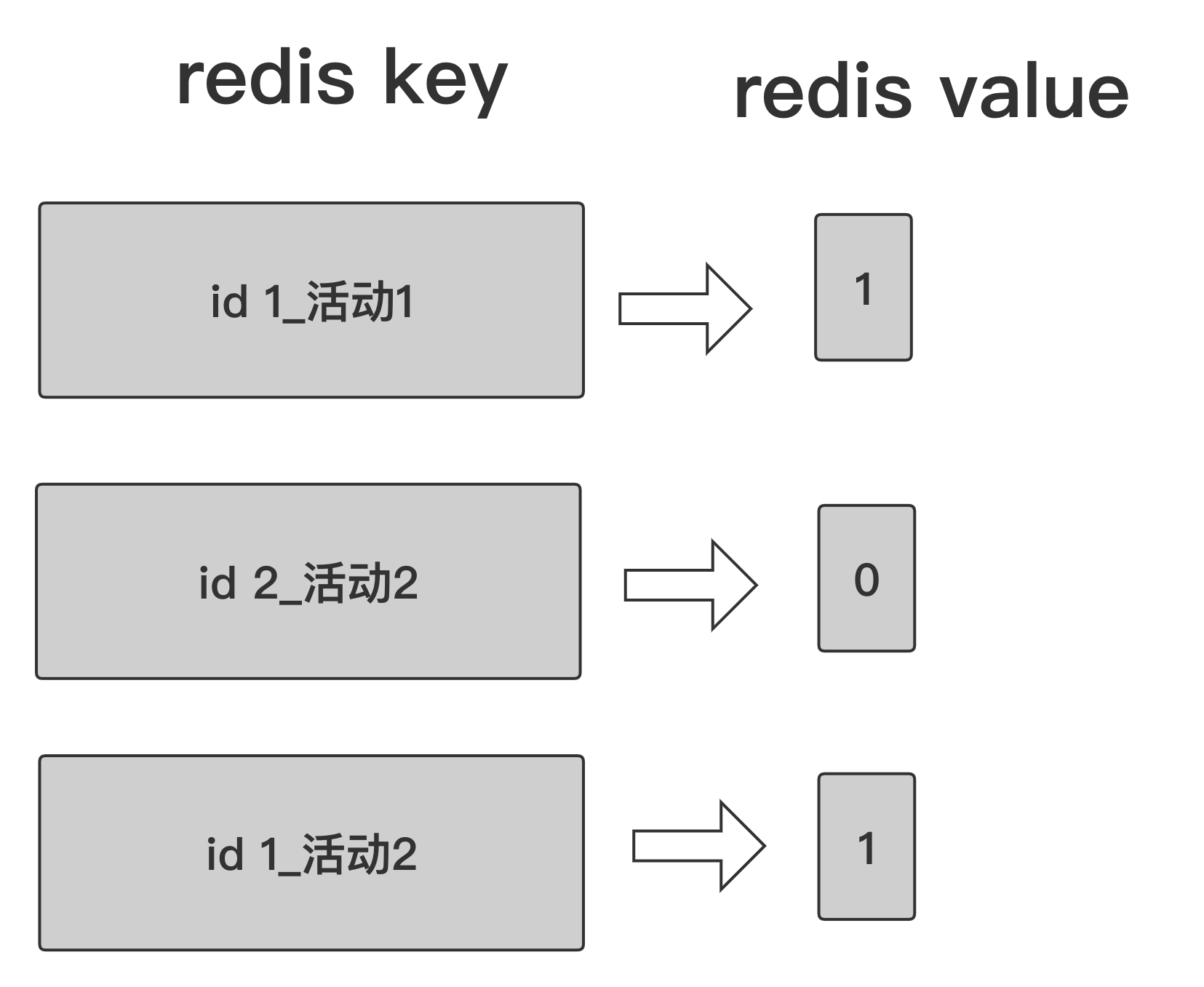
这种场景下,如果有 1 亿用户,需要同时计算 50 个活动或者 50 个不同维度下的 uv。那么理论上最大 key 数量为 1 亿 * 50 = 50 亿个 key。
Redis bit 方案:
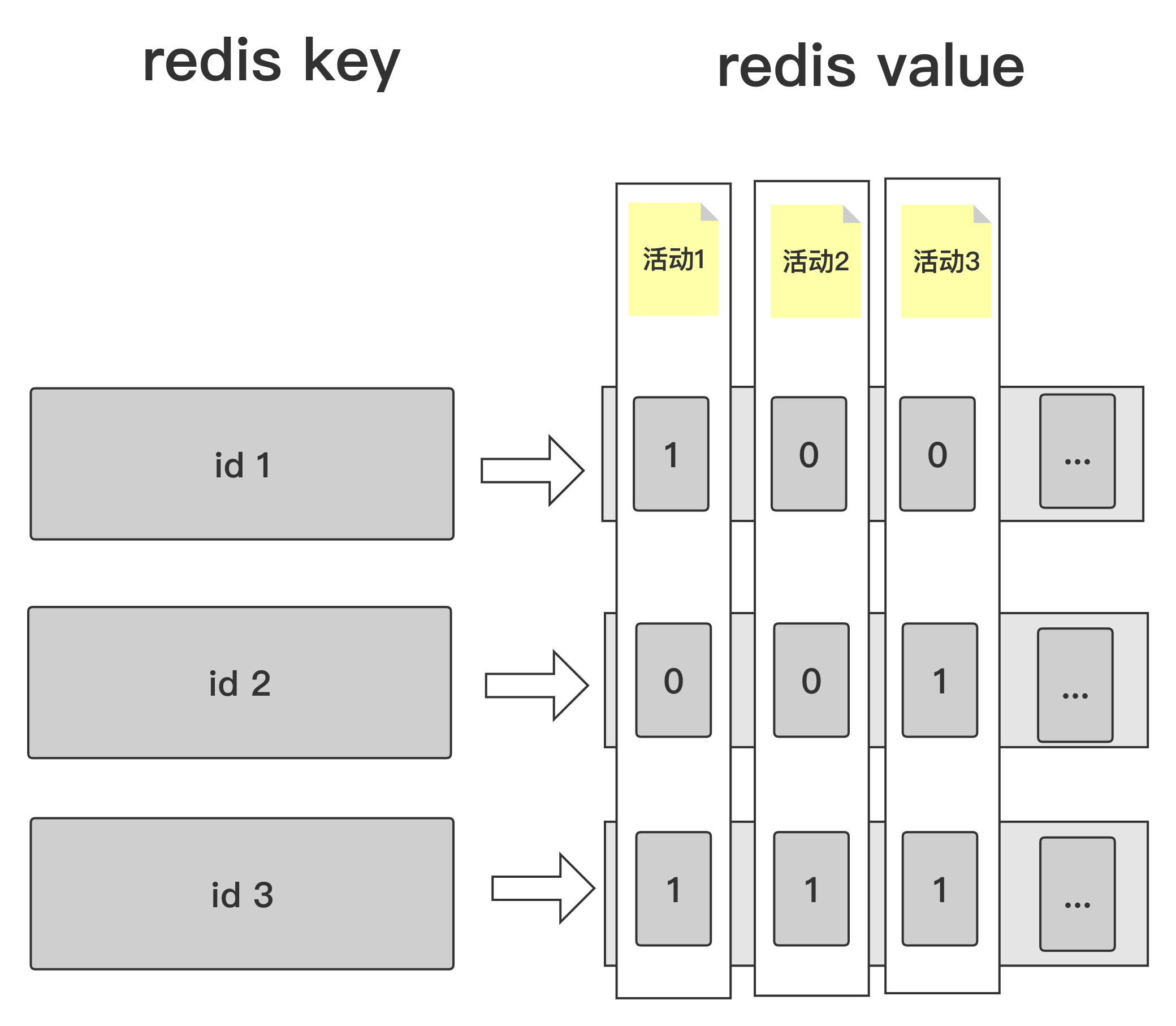
这样做的一个优点,就是这几十场活动的 uv 计算都使用了相同的 Redis key 来计算,可以大幅度减少 Redis 的容量占用。使用此方案的话,以上述相同的用户和活动场数,理论上最大
key 数量仅仅为 1 亿,只是 value 数量会多占几十个 bit。

