为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高
1 | static int indexFor(int hashcode, int length) { |
怎样提高get(key)效率?
怎样提高get(key)效率 = 怎样提高确定key的所在hashmap中数组index的效率
hashmap的数据结构是数组和链表的结合,所以我们当然希望这个hashmap里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!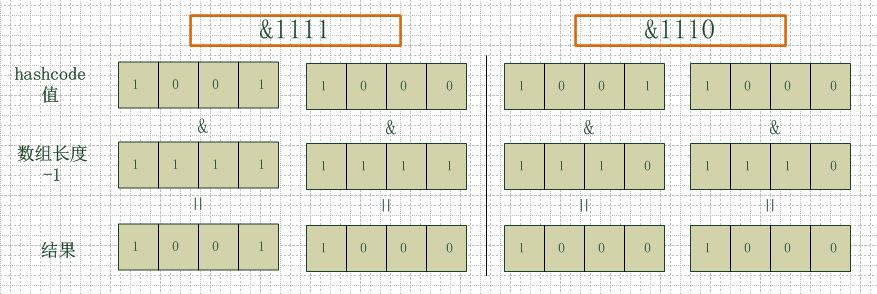
1.假设key的hashcode为h,数组长度为length,为了将数据打散,使hashmap中的数组下标对应的Entry链表都有数据,首先想到的就是对length取模,计算方法如下:
1 | static int indexFor(int h, int length) { |
因此确定了hashmap的indexFor函数的计算方式。
怎样确定hashmap数组的length
“模”运算的消耗还是比较大的,能不能找一种更快速,消耗更小的方式?我们发现做位运算的消耗是很小的,所以尝试将取模运算转换成位预算,由此发现length为2的n次方时会有
1 | static int indexFor(int h, int length) { |
由于 & 运算符计算效率大大高于 % 运算符,所以上述计算转换为:
1 | static int indexFor(int h, int length) { |
也规定了 length 必须是2的n次方(n>0)
除此之外,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!

