Apache Flink 学习:异步IO之RichAsyncFunction
问题
设置kafka consumer并行度的语义
1.如果设置kafka consumer的并发度为100,并且申请到集群中资源的Task Manager的slot个数也为100个,则每个slot中运行的任务都生成这么多数量的kafka consumer,还是每个slot一个kafka consumer?
2.场景:一个keyBy过后设置了一分钟的窗口dataStream中,如果保证每次触发这个窗口时,窗口的数据永远只有一条的话,并且在保证窗口为1分钟大小的情况下,接口返回速度保证在10秒,使用Async IO是否就没有意义了,因为当前请求队列里面只有一条数据
3.flink 默认执行一个Job的slot中线程数为什么是8,在哪里设置的
使用AsyncIO需要考虑的指标
1.每个slot中Flink Job的线程数
2.如果需要使用时间窗口:时间窗口的大小,几分钟的窗口
2.如果需要keyBy:每个slot中Flink Job的大概key的个数(什么情况使用,什么情况不使用)
简介
我们知道flink对于外部数据源的操作可以通过自带的连接器,或者自定义sink和source实现数据的交互,那么为啥还需要异步IO呢?
那时因为对于实时处理,当我们需要使用外部存储数据参与计算时,与外部系统之间的交互延迟对流处理的整个工作进度起决定性的影响。
如果我们是使用传统方式mapfunction等算子里访问外部存储,实际上该交互过程是同步的,比如下图中:请求a发送到数据库,那么function会一直等待响应。在很多案例中,这个等待过程是非常浪费函数时间的。
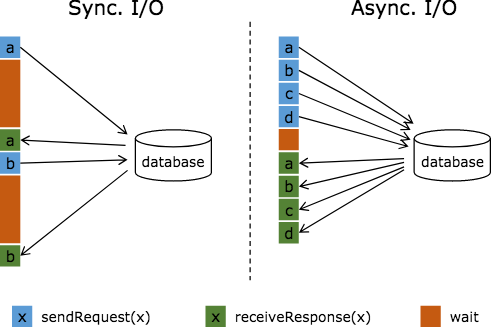
图中棕色的长条表示等待时间,可以发现网络等待时间极大地阻碍了吞吐和延迟。为了解决同步访问的问题,异步模式可以并发地处理多个请求和回复。
也就是说,你可以连续地向数据库发送用户a、b、c等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示。
这也正是 Async I/O 的实现原理。
目的
将MapFunction或者FlatMapFunction中的同步访问外部存储设备的方法通过AsyncFunction替换以实现异步访问
在执行过程中,如果使用了keyBy,则相同的key整个执行周期都使用同一个线程,但是不同的key也可以使用同一个线程
如何使用Async I/O
我们需要自定义一个类实现RichAsyncFunction这个抽象类,实现其中的抽象方法,这点和自定义source很像。
主要是的抽象方法如下,然后在asyncInvoke()使用CompletableFuture执行异步操作(CompletableFuture会提供一个ForkJoinPool作为请求线程池)
1 | public void open(Configuration parameters) throws Exception; |
然后在AsyncDataStream中使用我们定义好的类,去实现主流异步的访问外部数据源
原理实现
AsyncDataStream.(un)orderedWait 的主要工作就是创建了一个 AsyncWaitOperator。
AsyncWaitOperator 是支持异步 IO 访问的算子实现,该算子会运行 AsyncFunction 并处理异步返回的结果,其内部原理如下图所示
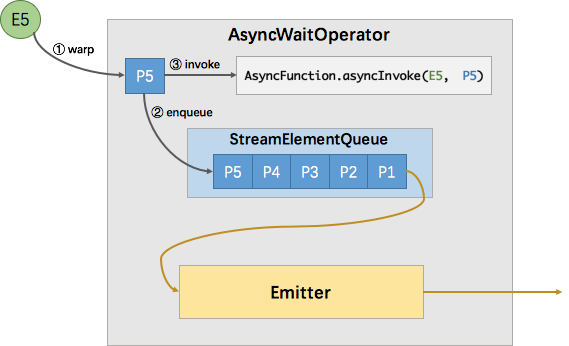
如图所示,AsyncWaitOperator 主要由两部分组成:StreamElementQueue 和 Emitter。
StreamElementQueue 是一个 Promise 队列,所谓 Promise 是一种异步抽象表示将来会有一个值(参考 Scala Promise 了解更多),这个队列是未完成的 Promise 队列,也就是进行中的请求队列。
Emitter 是一个单独的线程,负责发送消息(收到的异步回复)给下游。
图中E5表示进入该算子的第五个元素(”Element-5”),在执行过程中首先会将其包装成一个 “Promise” P5,然后将P5放入队列。
最后调用 AsyncFunction 的 ayncInvoke 方法,该方法会向外部服务发起一个异步的请求,并注册回调。
该回调会在异步请求成功返回时调用 AsyncCollector.collect 方法将返回的结果交给框架处理。
实际上 AsyncCollector 也一个 Promise,也就是 P5,在调用 collect 的时候会标记 Promise 为完成状态,并通知 Emitter 线程有完成的消息可以发送了。
Emitter 就会从队列中拉取完成的 Promise ,并从 Promise 中取出消息发送给下游。
消息的顺序性
上文提到 Async I/O 提供了两种输出模式。
其实细分有三种模式: 有序,ProcessingTime 无序,EventTime 无序。
Flink 使用队列来实现不同的输出模式,并抽象出一个队列的接口(StreamElementQueue),这种分层设计使得AsyncWaitOperator和Emitter不用关心消息的顺序问题。
StreamElementQueue有两种具体实现,分别是 OrderedStreamElementQueue 和 UnorderedStreamElementQueue。
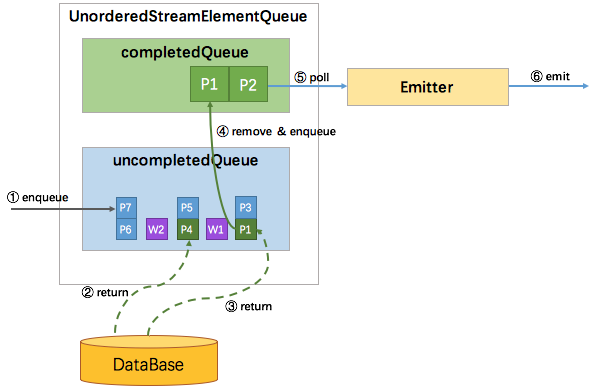
UnorderedStreamElementQueue 比较有意思,它使用了一套逻辑巧妙地实现完全无序和 EventTime 无序
有序
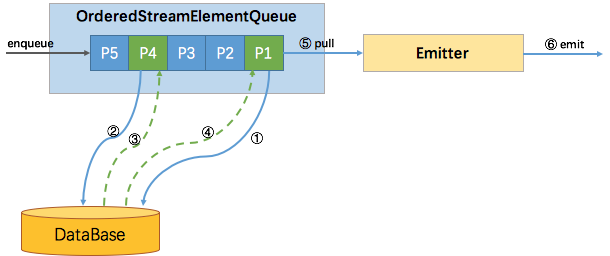
有序比较简单,使用一个队列就能实现。
所有新进入该算子的元素(包括 watermark),都会包装成 Promise 并按到达顺序放入该队列。
如下图所示,尽管P4的结果先返回,但并不会发送,只有 P1 (队首)的结果返回了才会触发 Emitter 拉取队首元素进行发送
ProcessingTime 无序
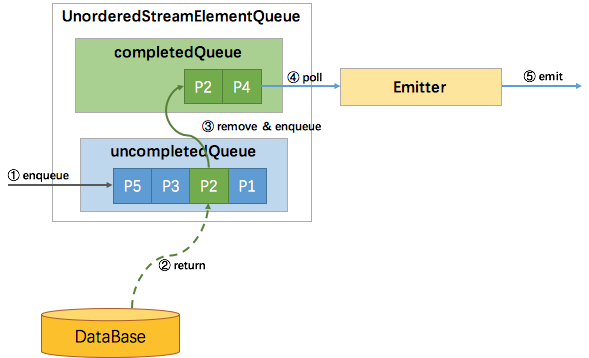
ProcessingTime 无序也比较简单,因为没有 watermark,不需要协调 watermark 与消息的顺序性,所以使用两个队列就能实现,一个 uncompletedQueue 一个 completedQueue。
所有新进入该算子的元素,同样的包装成 Promise 并放入 uncompletedQueue 队列,当uncompletedQueue队列中任意的Promise返回了数据,则将该 Promise 移到 completedQueue 队列中,并通知 Emitter 消费。
如下图所示:
EventTime 无序
EventTime 无序类似于有序与 ProcessingTime 无序的结合体。
因为有 watermark,需要协调 watermark 与消息之间的顺序性,所以uncompletedQueue中存放的元素从原先的 Promise 变成了 Promise 集合。
如果进入算子的是消息元素,则会包装成 Promise 放入队尾的集合中。
如果进入算子的是 watermark,也会包装成 Promise 并放到一个独立的集合中,再将该集合加入到 uncompletedQueue 队尾,最后再创建一个空集合加到 uncompletedQueue 队尾。
这样,watermark 就成了消息顺序的边界。
只有处在队首的集合中的 Promise 返回了数据,才能将该 Promise 移到 completedQueue 队列中,由 Emitter 消费发往下游。
只有队首集合空了,才能处理第二个集合。这样就保证了当且仅当某个 watermark 之前所有的消息都已经被发送了,该 watermark 才能被发送。过程如下图所示:
说明
1、AsyncDataStream有2个方法,unorderedWait表示数据不需要关注顺序,处理完立即发送,orderedWait表示数据需要关注顺序,为了实现该目标,操作算子会在该结果记录之前的记录为发送之前缓存该记录。这往往会引入额外的延迟和一些Checkpoint负载,因为相比于无序模式结果记录会保存在Checkpoint状态内部较长的时间。
2、Timeout配置,主要是为了处理死掉或者失败的任务,防止资源被长期阻塞占用。
3、最后一个参数Capacity表示同时最多有多少个异步请求在处理,异步IO的方式会导致更高的吞吐量,但是对于实时应用来说该操作也是一个瓶颈。限制并发请求数,算子不会积压过多的未处理请求,但是一旦超过容量的显示会触发背压。
该参数可以不配置,但是默认是100

